GRPO might not be the best choice for multi-task RL training
I’ve been testing different critic-free RL algos on multi-task environments, and one thing I’ve noticed is that GRPO (Deepseek, 2024) seems to slightly underperform normalization-free variants. This tracks with the results in the LOOP paper (Chen et al., 2025).
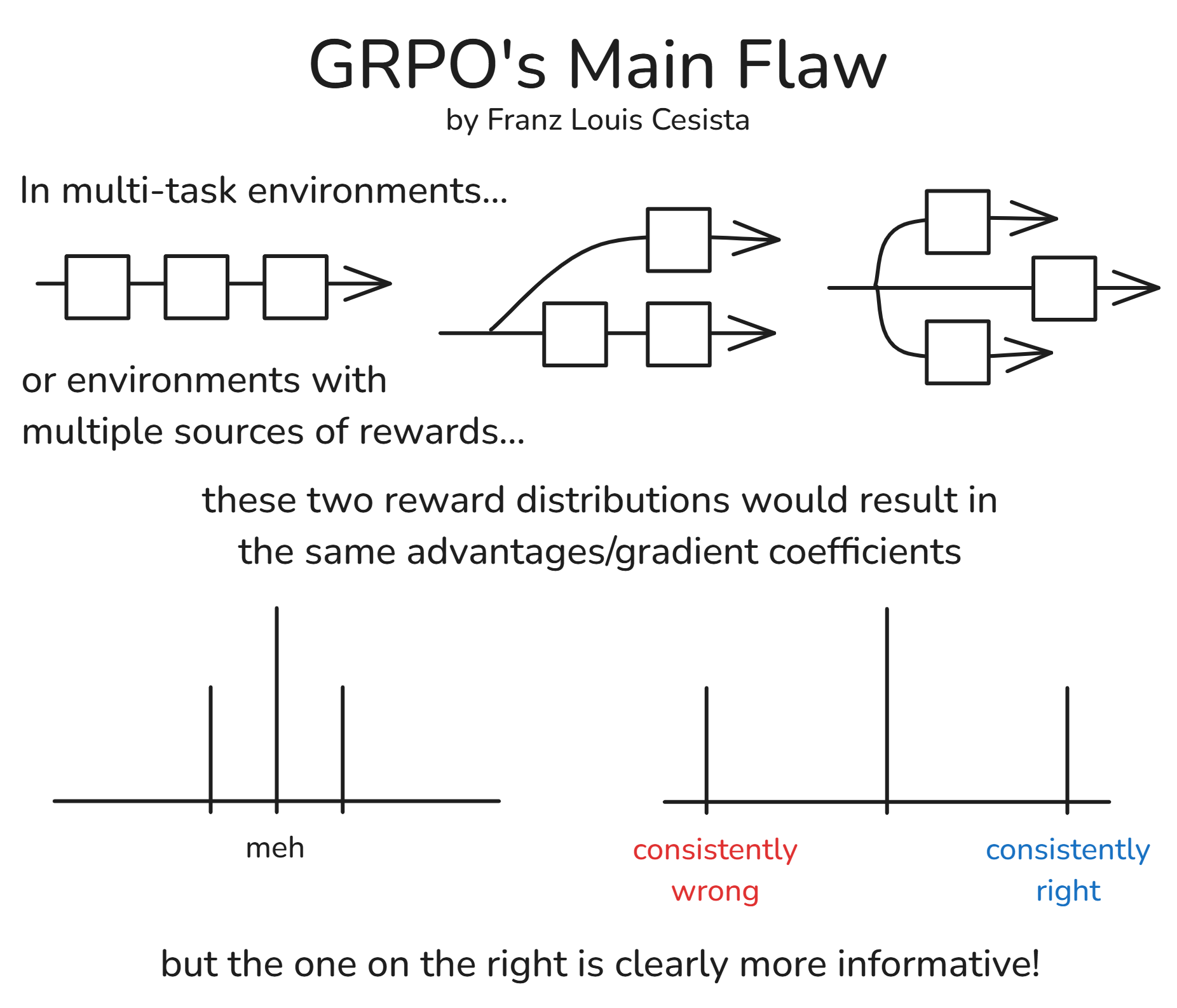
Why? Most likely because GRPO’s normalization term, in a sense, penalizes large magnitude rewards. But in multi-task envs, these rewards are highly informative!
E.g.:
- If your agent gets a very low (negative) reward, then it must be getting things consistently wrong–and this must be punished severely. And
- If it gets a very high reward, then it must be getting things consistently right–and this must be encouraged a lot more.
More concrete example
Suppose we have 5+ sources of rewards per rollout and we sample 7 rollouts per iteration. And suppose,
At iteration 1, we get:
- Rewards:
[-1, -1, -1, 0, 1, 1, 1] - Advantages:
[-1.08, -1.08, -1.08, 0, 1.08, 1.08, 1.08]
And at iteration 2, we get:
- Rewards:
[-5, -5, -5, 0, 5, 5, 5] - Advantages:
[-1.08, -1.08, -1.08, 0, 1.08, 1.08, 1.08]
The reward distribution in the second iteration is clearly more informative than the first because the agents are either getting things consistently right or consistently wrong. Yet, we get the same advantages with GRPO! This is problematic.
Why haven’t Deepseek and the rest of the open-source community caught this yet?
Because it doesn’t matter for the way we currently train our reasoning LLMs anyway. We only have one source of rewards: the verifier at the end of the generation step.
But this is going to be a problem when you try to train an agent that needs to complete multiple (verifiable) tasks per run (e.g. a browser agent). Be careful!
Yes, the goal of introducing a baseline is to reduce the variance of the gradient estimator to stabilize training. But this is the kind of variance we don’t want to get rid of!
How to cite
@misc{cesista2025grpoflaw,
author = {Franz Louis Cesista},
title = {{GRPO}'s Main Flaw},
year = {2025},
month = {February},
day = {11},
url = {https://leloykun.github.io/ponder/grpo-flaw/},
}
References
- Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y.K., Wu, Y., & Guo, D. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. URL https://arxiv.org/abs/2402.03300
- Chen, K., Cusumano-Towner, M., Huval, B., Petrenko, A., Hamburger, J., Koltun, V., & Krähenbühl, P. (2025). Reinforcement Learning for Long-Horizon Interactive LLM Agents. URL https://arxiv.org/abs/2502.01600