If you find this post useful, please consider supporting my work by sponsoring me on GitHub:
1. Introduction
Here I’ll discuss a fast, numerically stable, and (auto-)differentiable way to perform spectral clipping, i.e., clipping the singular values of a matrix to a certain range. This is useful in deep learning because it allows us to control the ‘growth’ of our weights and weight updates, enabling faster and stabler feature learning (Yang et al., 2024; Large et al., 2024). As discussed in Section 2.2 of Ponder: Muon and a Selective Survey on Steepest Descent in Riemannian and Non-Riemannian Manifolds,
If we want the Euclidean norm of our features and feature updates to ‘grow’ with the model size, then the Spectral norm of our weights and weight updates must also ‘grow’ with the model size.
There are multiple ways to control the spectral norm of our (matrix-structured) weights and weight updates. One is to “pull” all of the singular values to some target value chosen a priori via the matrix sign function $\texttt{msign}$. This is what the Muon optimizer already does, but only on the weight updates: it takes the raw gradient and tries to “pull” its as many of its singular values to $\sqrt{\frac{d_{out}}{d_{in}}}$. This guarantees that the update step merely changes the activation RMS-norm of that layer by at most $1$ unit. We could also apply this process to the weights after every update step to guarantee that the weight norms would not blow up, but constraining the weight space to the Stiefel manifold is too strong of a constraint. We discuss more of this in our upcoming preprint. For now, we will focus on Spectral Clipping:
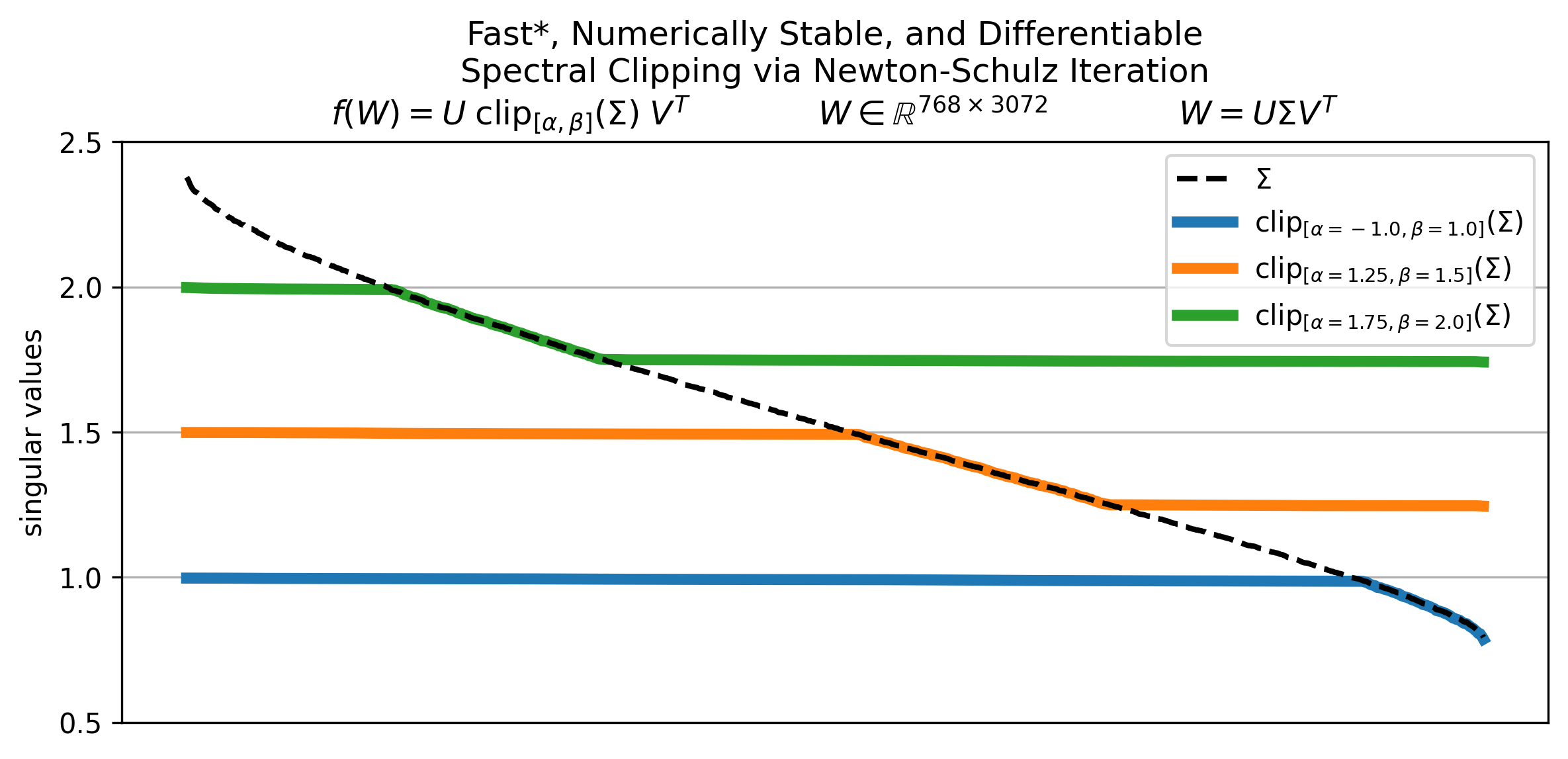
Definition 1 (Spectral Clipping). Let $W \in \mathbb{R}^{m \times n}$ and $W = U \Sigma V^T$ be its singular value decomposition where $\Sigma = (\sigma_1, \ldots, \sigma_{min(m,n)})$ are the singular values of $W$. Then we define Spectral Clipping as the following matrix function $\texttt{spectral\_clip}_{[\sigma_{min}, \sigma_{max}]}: \mathbb{R}^{m \times n} \to \mathbb{R}^{m \times n}$,
$$\begin{equation}\texttt{spectral\_clip}_{[\sigma_{min}, \sigma_{max}]}(W) = U \texttt{clip}_{[\sigma_{min}, \sigma_{max}]}(\Sigma) V^T \label{eq:spectralclipdef}\end{equation}$$where $\sigma_{min}, \sigma_{max} \in [0, \infty)$ are hyperparameters that control the minimum and maximum attainable singular values of the resulting matrix and $\texttt{clip}_{[\alpha, \beta]}: \mathbb{R} \to \mathbb{R}$ is applied element-wise on the singular values of $W$,
$$\begin{equation}\texttt{clip}_{[\alpha, \beta]}(x) = \begin{cases} \alpha & \texttt{if } x < \alpha \\ x & \texttt{if } \alpha \leq x \leq \beta \\ \beta & \texttt{if } \beta < x \end{cases}\end{equation}$$where $\alpha, \beta \in \mathbb{R} \cup \{-\infty, \infty\}$ and $\alpha \leq \beta$.
Note that since the singular values of a matrix are guaranteed to be non-negative, $\texttt{clip}$ above does not need to be bidirectional. And setting $\alpha \leq 0$ and/or $\beta = \infty$ massively simplifies our (matrix) function, resulting in efficiency gains,
- $\texttt{clip}_{[\leq 0, \beta]}(x) = \min(x, \beta)$; and
- $\texttt{clip}_{[\alpha, \infty]}(x) = \max(x, \alpha)$ which is simply the (shifted-)$\texttt{ReLU}$.
In practice, the former would suffice for constraining the weights of neural networks. However, we will keep both parameters $\alpha, \beta$ in this work for generality and in case one would need to constrain the weights to always be full rank to prevent the activations from collapsing in dimension.
1.1. Potential applications to test-time training (TTT)
As discussed in previous posts, (linear) attention mechanisms implicitly or explicitly perform test-time training (TTT) by learning to adapt the attention state as the model ingests more and more context without updating the model parameters. The core idea behind this is that we can hardcode a subnetwork and its optimizer into the model architecture itself and if this subnetwork-optimizer pair is end-to-end (auto-)differentiable, then in theory this should allow the model to learn methods on how to learn from the context it ingests which it can then use at test-time.
Recent work in this direction focuses on optimizing speed, stability, and expressiveness of such architectures (Yang et al., 2025; Grazzi et al., 2025). Hence the design choices in this post. In theory, we could use $\texttt{spectral\_clip}$ we construct here as an inner optimizer in a (linear) attention mechanism. In fact the team behind Atlas (Behrouz et al., 2025) has recently shown that the Muon optimizer (Jordan et al., 2024) can indeed be incorporated into an attention mechanism and that doing so not only improves performance but also reduces accuracy drop at longer context lengths. And as previously discussed by Su (2025a),
$$\lim_{k \to \infty}\texttt{spectral\_clip}(kG) = \texttt{msign}(G)$$for $k \in \mathbb{R}$. Thus, we could simply swap in Muon’s orthogonalization step with spectral clipping with minimal changes to the architecture. Alternatively, we could also apply it after applying Muon optimizer’s update step to control the growth of the attention state and prevent it from blowing up. Think of this as a more theoretically-grounded way of constraining the weights vs. weight decay.
1.2. Potential applications to robotics and AI safety
Ideally, we want our robots’ behavior to be ‘smooth’ and stable relative to the inputs they receive. E.g., in robotics and self-driving, we do not want random noise or sensory errors to cause sudden and massive changes in the robot’s behavior, potentially killing the humans around it. Likewise, for large language models, we do not want small changes in the prompt or embeddings to cause the model to suddenly misbehave after training.
We can measure this “sensitivity” of the model’s behavior to changes in the inputs via the Lipschitz constant of the model. The smaller it is, the more ‘stable’ the model is. And we can control the Lipschitz bound by controlling the weight norms. Here, I will discuss multiple ways to do this.
Definition 2 (Lipschitz). Let $f: \mathbb{R}^n \to \mathbb{R}^m$ be a function, then $f$ is said to be $L$-Lipschitz continuous if there exists a constant $L \geq 0$ such that for all $x, y \in \mathbb{R}^n$,
$$\| f(x) - f(y) \| \leq L\|x - y\|$$for some norm $\| \cdot \|$ chosen a priori.
2. Towards hardware-architecture-optimizer codesign
In deep learning, we not only have to be mindful of architecture-optimizer codesign but also hardware-software codesign. That is, architectural and optimizer choices and how we implement them have to be hardware-aware so that we can squeeze as much performance as we can from our GPUs/TPUs.
For example, the naive way to compute Spectral Clipping is to directly compute the SVD, clip the singular values we get from it, then reconstruct the matrix using the clipped singular values. A JAX implementation would look like this:
def naive_spectral_clip(W: jax.Array, sigma_min: float=-1., sigma_max: float=1.) -> jax.Array:
U, S, Vt = jnp.linalg.svd(W, full_matrices=False)
S_clipped = jnp.clip(S, min=sigma_min, max=sigma_max)
return U @ jnp.diag(S_clipped) @ Vt
However, this is not recommended because computing the SVD directly (1) does not take advantage of the GPUs’ tensor cores and (2) requires higher numerical precision, typically 32-bit float types. These not only slow things down but also increase precious memory usage, making it hard to scale to larger models.
Ideally, we want to only use operations that (1) have fast implementations on GPUs/TPUs and (2) are stable under lower numerical precision, e.g., 16-bit, 8-bit, even 4-bit float types. So, elementwise operations like matrix addition and scalar multiplication, matrix multiplication, matrix-vector products, among others are preferred, but not operations like matrix inversions or SVD decomposition, etc. With the proper coefficients, (semi-)orthogonalization via Newton-Schulz iteration for computing the matrix sign function has also been shown to be fast and numerically stable under lower precision (Jordan et al., 2024), thus we can use that here.
2.1. Finding a suitable surrogate function for $\texttt{clip}$
This is the fun part.
So, how do we compute spectral clipping while only using simple, but fast & numerically stable operations? First, let’s list the operations we can actually use and consider how they act on the matrix itself and its singular values. There are more operations we can use that aren’t listed here, but these would suffice for our problem.
| Operation | Matrix form | Action on singular values | Tensor cores utilization | Numerical stability at low precision | (Auto-)differentiable |
|---|---|---|---|---|---|
| Linear combination | $c_1 W_1 + c_2 W_2$ | $c_1 \Sigma_1 + c_2 \Sigma_2$ | $\color{green}{\text{high}}$ | $\color{green}{\text{yes}}$ | $\color{green}{\text{yes}}$ |
| Apply polynomial function | $\texttt{p}(W)$ | $\texttt{p}(\Sigma)$ | $\color{green}{\text{high}}$ | $\color{green}{\text{yes}}$ | $\color{green}{\text{yes}}$ |
| Apply matrix sign function (via Newton-Schulz iteration) | $\texttt{msign}(W)$ | $\texttt{sign}(\Sigma)$ | $\color{green}{\text{high}}$ | $\color{green}{\text{yes}}$ | $\color{green}{\text{yes}}$ |
| Apply matrix sign function (via QR-decomposition) | $\texttt{msign}(W)$ | $\texttt{sign}(\Sigma)$ | $\color{orange}{\text{medium}}$ | $\color{green}{\text{yes}}$* ( bfloat16/float16+) | $\color{green}{\text{yes}}$ (in jax) |
| Apply matrix sign function (via SVD) | $\texttt{msign}(W)$ | $\texttt{sign}(\Sigma)$ | $\color{red}{\text{low}}$ | $\color{red}{\text{no}}$ ( float32+) | $\color{red}{\text{no}}$ |
Let’s reconstruct the $\mathbb{R} \to \mathbb{R}$ clipping on the singular values with these elementary functions first, then let’s use it to construct the matrix form. Here we take advantage of the following identity,
$$\begin{equation} |x| = x \cdot \texttt{sign}(x) \label{eq:absviasign} \end{equation}$$With this, we can now construct $\texttt{clip}$ as follows,

Proposition 3 (Computing $\texttt{clip}$ via $\texttt{sign}$). Let $\alpha, \beta \in \mathbb{R} \cup \{-\infty, \infty\}$ and $\texttt{clip}: \mathbb{R} \to \mathbb{R}$ be the clipping function defined in Definition 1. Then,
$$\begin{equation}\texttt{clip}_{[\alpha, \beta]}(x) = \frac{\alpha + \beta + (\alpha - x)\texttt{sign}(\alpha - x) - (\beta - x)\texttt{sign}(\beta - x)}{2} \label{eq:clipviasign} \end{equation}$$
Proof: It would suffice to show that, For this, we can simply check case-by-case, Combining Equations $\eqref{eq:absviasign}$ and $\eqref{eq:clipviaabs}$ then yields Equation $\eqref{eq:clipviasign}$. $\blacksquare$Show proof of Proposition 3
$x$ $\left\| \alpha - x \right\|$ $\| \beta - x \|$ $\frac{\alpha + \beta + \| \alpha - x \| - \| \beta - x \| }{2}$ $\texttt{clip}_{[\alpha, \beta]}(x)$ $x < \alpha$ $\alpha - x$ $\beta - x$ $\alpha$ $\alpha$ $\alpha \leq x \leq \beta $ $x - \alpha$ $\beta - x$ $x$ $x$ $\beta < x$ $x - \alpha$ $x - \beta$ $\beta$ $\beta$
2.2. Lifting to matrix form (the naive & incorrect way)

A naive way to lift Equation $\eqref{eq:clipviasign}$ above to matrix form is to simply replace the variables, scalar constants, and scalar (sub-)functions with their corresponding matrix form, i.e., replace $x$ with $W$, $1$ with $I$, and $\texttt{sign}(\cdot)$ with $\texttt{msign}(\cdot)$. This gives us the following matrix function,
$$\begin{align} \texttt{f}(W) &= \frac{1}{2} [(\alpha + \beta)I + (\alpha I - W) \texttt{msign}(\alpha I - W)^T \nonumber \\ &\qquad\qquad\qquad\;\;- (\beta I - W) \texttt{msign}(\beta I - W)^T] \end{align}$$However, as communicated to me by You Jiacheng & Su Jianlin, this does not work (see figure above) because $I$ may not share the same singular vectors as $W$.
Another problem is that $\texttt{f}$ does not preserve the dimensions of the input matrix $W$. To see this, note that both $\alpha I - W$ and $\texttt{msign}(\alpha I - W)$ have shape $m \times n$ and so $(\alpha I - W) \texttt{msign}(\alpha I - W)^T$ must have shape $m \times m$. The same is true for the other term.
$$\begin{aligned} \texttt{f}(W) &= \frac{1}{2} [(\alpha + \beta)I_{\color{red}{m \times m}} + (\alpha I - W) \texttt{msign}(\alpha I - W)^T\\ &\qquad\qquad\qquad\qquad\;\;- \underbrace{\underbrace{(\beta I - W)}_{m \times n} \underbrace{\texttt{msign}(\beta I - W)^T}_{n \times m}}_{\color{red}{m \times m}}] \end{aligned}$$2.3. Lifting to matrix form (the proper way)

To properly lift Equation $\eqref{eq:clipviasign}$ to matrix form, let’s combine it with Equation $\eqref{eq:spectralclipdef}$,
$$\begin{align} \texttt{spectral\_clip}_{[\alpha, \beta]}(W) &= U \texttt{clip}_{[\alpha, \beta]}(\Sigma) V^T\nonumber\\ &= U \frac{(\alpha + \beta) I + (\alpha I - \Sigma)\texttt{sign}(\alpha I - \Sigma) - (\beta I - \Sigma)\texttt{sign}(\beta I - \Sigma)}{2} V^T\nonumber\\ &= \frac{1}{2} [(\alpha + \beta) UV^T\nonumber\\ &\qquad+ U (\alpha I - \Sigma ) \texttt{sign}(\alpha I - \Sigma) V^T\nonumber\\ &\qquad- U (\beta I - \Sigma ) \texttt{sign}(\beta I - \Sigma) V^T]\nonumber\\ &= \frac{1}{2} [(\alpha + \beta) UV^T\nonumber\\ &\qquad+ U (\alpha I - \Sigma ) (V^TV) \texttt{sign}(\alpha I - \Sigma) (U^TU) V^T\nonumber\\ &\qquad- U (\beta I - \Sigma ) (V^TV) \texttt{sign}(\beta I - \Sigma) (U^TU) V^T]\nonumber\\ &= \frac{1}{2} [(\alpha + \beta) UV^T\nonumber\\ &\qquad+ (\alpha UV^T - U\Sigma V^T) (V \texttt{sign}(\alpha I - \Sigma) U^T)(UV^T)\nonumber\\ &\qquad- (\beta UV^T - U\Sigma V^T) (V \texttt{sign}(\beta I - \Sigma) U^T)(UV^T)]\nonumber\\ &= \frac{1}{2} [(\alpha + \beta) UV^T\nonumber\\ &\qquad+ (\alpha UV^T - U\Sigma V^T) (U \texttt{sign}(\alpha I - \Sigma) V^T)^T(UV^T)\nonumber\\ &\qquad- (\beta UV^T - U\Sigma V^T) (U \texttt{sign}(\beta I - \Sigma) V^T)^T(UV^T)]\nonumber\\ &= \frac{1}{2} [(\alpha + \beta) \texttt{msign}(W)\nonumber\\ &\qquad+ (\alpha \cdot\texttt{msign}(W) - W) \texttt{msign}(\alpha \cdot\texttt{msign}(W) - W)^T\texttt{msign}(W)\nonumber\\ &\qquad- (\beta \cdot\texttt{msign}(W) - W) \texttt{msign}(\beta \cdot\texttt{msign}(W) - W)^T\texttt{msign}(W)]\nonumber\\ \texttt{spectral\_clip}_{[\alpha, \beta]}(W) &= \frac{1}{2} [(\alpha + \beta)I\nonumber\\ &\qquad+ (\alpha \cdot\texttt{msign}(W) - W) \texttt{msign}(\alpha \cdot\texttt{msign}(W) - W)^T\nonumber\\ &\qquad- (\beta \cdot\texttt{msign}(W) - W) \texttt{msign}(\beta \cdot\texttt{msign}(W) - W)^T\nonumber\\ &\qquad]\;\texttt{msign}(W) \label{eq:spectralclipviamsign} \end{align}$$And voilà, we’re done. The following code implements this in JAX,
def spectral_clip(W: jax.Array, alpha: float=-1., beta: float=1.) -> jax.Array:
if transpose := W.shape[0] > W.shape[1]:
W = W.T
OW = _orthogonalize_via_newton_schulz(W)
result = (1/2) * (
(alpha + beta) * jnp.eye(W.shape[0], dtype=W.dtype)
+ (alpha * OW - W) @ _orthogonalize_via_newton_schulz(alpha * OW - W).T
- (beta * OW - W) @ _orthogonalize_via_newton_schulz(beta * OW - W).T
) @ OW
if transpose:
result = result.T
return result
where _orthogonalize_via_newton_schulz above implements Jordan et al.’s (2024) Newton-Schulz iteration for computing the matrix sign function. Note that we’re calling _orthogonalize_via_newton_schulz thrice here, which is not ideal.
2.4. Optimization via abstract algebra
June 24, 2025 Update: This section builds on top of Su’s (2025c) blog post in response to this work.
Proposition 4 (Transpose Equivariance and Unitary Multiplication Equivariance of Odd Matrix Functions). Let $W \in \mathbb{R}^{m \times n}$ and $W = U \Sigma V^T$ be its singular value decomposition. And let $f: \mathbb{R}^{m \times n} \to \mathbb{R}^{m \times n}$ be an odd analytic matrix function that acts on the singular values of $W$ as follows,
$$f(W) = U f(\Sigma) V^T.$$Then $f$ is equivariant under transposition and unitary multiplication, i.e.,
$$\begin{align*} f(W^T) &= f(W)^T \\ f(WQ^T) &= f(W)Q^T \quad\forall Q \in \mathbb{R}^{m \times n} \text{ such that } Q^TQ = I_n \\ f(Q^TW) &= Q^Tf(W) \quad\forall Q \in \mathbb{R}^{m \times n} \text{ such that } QQ^T = I_m \end{align*}$$
Proof. Since $f$ is odd and analytic, we can decompose it as, for some coefficients $a_k \in \mathbb{R}$. Then, Hence $f$ is transpose equivariant. Likewise, for arbitrary $Q \in \mathbb{R}^{m \times n}$ such that $Q^TQ = I_n$, and for arbitrary $Q \in \mathbb{R}^{m \times n}$ such that $QQ^T = I_m$, Hence $f$ is unitary multiplication equivariant. $\blacksquare$Show proof of Proposition 4
Since $\texttt{msign}$ is odd, analytic, and always results in an orthogonal matrix, then,
$$\begin{aligned} \texttt{msign}(c\cdot\texttt{msign}(W) - W)^T \texttt{msign}(W) &= \texttt{msign}(c\cdot\texttt{msign}(W)^T - W^T) \texttt{msign}(W)\\ &= \texttt{msign}(c\cdot\texttt{msign}(W)^T\texttt{msign}(W) - W^T\texttt{msign}(W))\\ \texttt{msign}(c\cdot\texttt{msign}(W) - W)^T \texttt{msign}(W) &= \texttt{msign}(cI - W^T\texttt{msign}(W)) \end{aligned}$$or equivalently,
$$\texttt{msign}(W)^T\texttt{msign}(c\cdot\texttt{msign}(W) - W) = \texttt{msign}(cI - \texttt{msign}(W)^TW)$$Thus we can rewrite Equation $\eqref{eq:spectralclipviamsign}$ as,
$$\begin{align} \texttt{spectral\_clip}_{[\alpha, \beta]}(W) &= \frac{1}{2} [(\alpha + \beta)\texttt{msign}(W)\nonumber\\ &\qquad+ (\alpha \cdot\texttt{msign}(W) - W)\texttt{msign}(\alpha I - W^T\texttt{msign}(W))\\ &\qquad- \underbrace{(\beta \cdot\texttt{msign}(W) - W)}_{\color{blue}{m \times n}}\underbrace{\texttt{msign}(\beta I - W^T\texttt{msign}(W))}_{\color{blue}{n \times n}}]\nonumber\\ \end{align}$$or equivalently,
$$\begin{align} \texttt{spectral\_clip}_{[\alpha, \beta]}(W) &= \frac{1}{2} [(\alpha + \beta)\texttt{msign}(W)\nonumber\\ &\qquad+ \texttt{msign}(\alpha I - \texttt{msign}(W)^TW)(\alpha \cdot\texttt{msign}(W) - W)\\ &\qquad- \underbrace{\texttt{msign}(\beta I - \texttt{msign}(W)^TW)}_{\color{blue}{m \times m}}\underbrace{(\beta \cdot\texttt{msign}(W) - W)}_{\color{blue}{m \times n}}]\nonumber\\ \end{align}$$which is faster to compute than Equation $\eqref{eq:spectralclipviamsign}$ when $m \ll n$.
We can implement this in JAX as follows,
def spectral_clip_v2(W: jax.Array, sigma_min: float=-1., sigma_max: float=1.) -> jax.Array:
if transpose := W.shape[0] > W.shape[1]:
W = W.T
OW = _orthogonalize_via_newton_schulz(W)
result = (1/2) * (
(sigma_min + sigma_max) * OW
+ _orthogonalize_via_newton_schulz(sigma_min * jnp.eye(W.shape[0], dtype=W.dtype) - OW @ W.T) @ (sigma_min * OW - W)
- _orthogonalize_via_newton_schulz(sigma_max * jnp.eye(W.shape[0], dtype=W.dtype) - OW @ W.T) @ (sigma_max * OW - W)
)
if transpose:
result = result.T
return result
Note that we still call _orthogonalize_via_newton_schulz thrice here. However, two of those are on matrices of shape $m \times m$ and so the whole thing should be faster when $m < n$.
3. Variants
3.1. Sanity check: orthogonalization and scaling
As a simple test-case, let’s verify that setting the lower and upper bounds to be equal results in orthogonalization and scaling of the input matrix, i.e., $\texttt{spectral\_clip}_{[\sigma, \sigma]}(W) = \sigma \cdot \texttt{msign}(W)$. From Equation $\eqref{eq:spectralclipviamsign}$ we have,
$$\begin{aligned} \texttt{spectral\_clip}_{[\sigma, \sigma]}(W) &= \frac{1}{2} [(\sigma + \sigma)I\nonumber\\ &\qquad\cancel{+ (\sigma \cdot\texttt{msign}(W) - W) \texttt{msign}(\sigma \cdot\texttt{msign}(W) - W)^T}\nonumber\\ &\qquad\cancel{- (\sigma \cdot\texttt{msign}(W) - W) \texttt{msign}(\sigma \cdot\texttt{msign}(W) - W)^T}\nonumber\\ &\qquad]\;\texttt{msign}(W)\\ \texttt{spectral\_clip}_{[\sigma, \sigma]}(W) &= \sigma \cdot \texttt{msign}(W)\quad\blacksquare \end{aligned}$$3.2. Unbounded above: Spectral (Shifted-)ReLU

If we only want to bound the singular values from below, we set $\beta = +\infty$ in Equation $\eqref{eq:clipviasign}$. First note that for a fixed $x \in [0, \infty)$,
$$\lim_{\beta \to +\infty} \texttt{sign}(\beta - x) = +1$$Thus,
$$\begin{align} \texttt{clip}_{[\alpha, +\infty]}(x) &= \lim_{\beta \to +\infty}\frac{\alpha + \beta + (\alpha - x)\texttt{sign}(\alpha - x) - (\beta - x)\texttt{sign}(\beta - x)}{2}\nonumber\\ &= \frac{\alpha + \cancel{\beta} + (\alpha - x)\texttt{sign}(\alpha - x) - \cancel{\beta} + x}{2}\nonumber\\ \texttt{clip}_{[\alpha, +\infty]}(x) &= \frac{\alpha + x + (\alpha - x)\texttt{sign}(\alpha - x)}{2} \end{align}$$And following the approach above, we get,
$$\begin{align} \texttt{spectral\_relu}_\alpha(W) &= \texttt{spectral\_clip}_{[\alpha, +\infty]}(W) \nonumber \\ &= \frac{1}{2} [\alpha \cdot \texttt{msign}(W) + W \nonumber \\ &\qquad+ (\alpha \cdot\texttt{msign}(W) - W) \texttt{msign}(\alpha \cdot\texttt{msign}(W) - W)^T \texttt{msign}(W)] \end{align}$$The following code implements this in JAX,
def spectral_relu(W: jax.Array, alpha: float=1.) -> jax.Array:
if transpose := W.shape[0] > W.shape[1]:
W = W.T
OW = _orthogonalize_via_newton_schulz(W)
aW = alpha * OW - W
result = (1/2) * (alpha*OW + W + aW @ _orthogonalize_via_newton_schulz(aW).T @ OW)
if transpose:
result = result.T
return result
3.3. Unbounded below: Spectral Hardcapping

Note: Su (2025a) calls this “Singular Value Clipping” or “SVC” while our upcoming paper calls this “Spectral Hardcapping”.
If we only want to bound the singular values from above, we set $\alpha = -\infty$ in Equation $\eqref{eq:clipviasign}$, i.e.,
$$\begin{align} \texttt{clip}_{[-\infty, \beta]}(x) &= \lim_{\alpha \to -\infty}\frac{\alpha + \beta + (\alpha - x)\texttt{sign}(\alpha - x) - (\beta - x)\texttt{sign}(\beta - x)}{2}\nonumber\\ &= \frac{\cancel{\alpha} + \beta - \cancel{\alpha} + x - (\beta - x)\texttt{sign}(\beta - x)}{2}\nonumber\\ \texttt{clip}_{[-\infty, \beta]}(x) &= \frac{\beta + x - (\beta - x)\texttt{sign}(\beta - x)}{2} \end{align}$$Setting $\beta = 1$ recovers Su’s (2025b) and You’s (2025) results. And following the approach above, we get,
$$\begin{align} \texttt{spectral\_hardcap}_\beta(W) &= \texttt{spectral\_clip}_{[-\infty, \beta]}(W) \nonumber \\ &= \frac{1}{2} [\beta \cdot \texttt{msign}(W) + W \nonumber \\ &\qquad- (\beta \cdot\texttt{msign}(W) - W) \texttt{msign}(\beta \cdot\texttt{msign}(W) - W)^T \texttt{msign}(W)] \end{align}$$The following code implements this in JAX,
def spectral_hardcap(W: jax.Array, beta: float=1.) -> jax.Array:
if transpose := W.shape[0] > W.shape[1]:
W = W.T
OW = _orthogonalize_via_newton_schulz(W)
aW = beta * OW - W
result = (1/2) * (beta*OW + W - aW @ _orthogonalize_via_newton_schulz(aW).T @ OW)
if transpose:
result = result.T
return result
We are now only calling _orthogonalize_via_newton_schulz twice here.
3.4. Spectral Clipped Weight Decay

Here we combine weight decay and spectral hardcapping by only applying the ‘decay’ term $\lambda$ to the singular values above a certain threshold $\beta$,
$$\begin{align} \texttt{clipped\_weight\_decay}_{\lambda,\beta}(x) &= (1-\lambda)x + \lambda\cdot\texttt{clip}_{[0, \beta]}(x) \nonumber \\ &= \begin{cases} x & \texttt{if } x \leq \beta\\ (1-\lambda)x + \lambda\beta & \texttt{if } x > \beta \\ \end{cases} \end{align}$$and,
$$\begin{align} \texttt{spectral\_clipped\_weight\_decay}_{\lambda,\beta}(W) &= U \texttt{clipped\_weight\_decay}_{\lambda,\beta}(\Sigma) V^T \nonumber \\ &= (1-\lambda) W + \lambda\cdot\texttt{spectral\_hardcap}_\beta(W) \end{align}$$And while it is unbounded above by itself, we can still use it to bound the spectral norm of the weights–assuming that we constrain the weight updates as discussed in previous sections. Liu et al. (2025), Pethick et al. (2025), and Liu (2025) have previously derived an equilibrium point for standard (decoupled) weight decay with the Muon optimizer, i.e., it “pulls” the weight norms towards $\frac{1}{\lambda}$. In our upcoming paper, we briefly discuss a more general way to derive such equilibrium points for various weight constraints. Here, we use the same trick to derive the equilibrium point for Spectral Clipped Weight Decay.
Claim 5 (Equilibrium Point of Spectral Clipped Weight Decay). Let $\eta \in (0, \infty)$ be the learning rate, $\lambda \in (0, 1]$ be the decay term, and $\beta \in (0, \infty)$ be the singular value threshold above which we start applying the decay term. Additionally, suppose that the weight updates are constrained to have norm $\|\Delta W\| \leq \eta$. Then Spectral Clipped Weight Decay has an equilibrium point $\sigma_{\text{eq}}$,
$$\begin{aligned} \sigma_{\text{eq}} = \begin{cases} \beta + \frac{1-\lambda}{\lambda}\eta & \texttt{if } \text{we take a gradient step first then project}\\ \beta + \frac{\eta}{\lambda} & \texttt{if } \text{we project first then take a gradient step} \end{cases} \end{aligned}$$which it “pulls” the spectral norm of the weights towards.
Proof. Let’s consider the first case where we take a gradient step first then project, By the subadditivity of norms, we have $\|W_t + \Delta W_t\| \leq \|W_t\| + \|\Delta W_t\| \leq \|W_t\| + \eta$. Thus, we can bound the spectral norm of the weights after every update step, Equality is achieved at $\sigma_{\text{eq}}$ where, And notice that singular values larger than $\sigma_{\text{eq}}$ decreases after every update step, since $1-\lambda < 1$, while singular values smaller than $\sigma_{\text{eq}}$ increases, Hence $\sigma_{\text{eq}}$ is indeed an equilibrium point. As for the second case where we project first then take a gradient step, we have, And so we have the equilibrium point, and we can verify that it is indeed an equilibrium point similarly to the first case.Show proof of Claim 5
Note that as we decay the learning rate to zero throughout training, the equilibrium point approaches $\beta$,
$$\sigma^*_{\text{eq}} = \lim_{\eta \to 0} \begin{cases} \beta + \frac{1-\lambda}{\lambda}\eta\\ \beta + \frac{\eta}{\lambda} \end{cases} = \beta$$Thus, unlike standard weight decay, we do not have to worry about the weights collapsing to zero as we dial down the learning rate. But if we want the equilibrium point to be independent of the learning rate, we have to go with the second case above where we project first then take a gradient step and set $\lambda_\text{decoupled} = \eta\lambda$ and the new equilibrium point becomes,
$$\sigma_{\text{eq,decoupled}} = \beta + \frac{1}{\lambda}$$Lastly, note that spectral clipped weight decay allows us to have much tighter weight norm bounds without being too aggressive with the decay. For example, to have an equilibrium point of $\sigma_{\text{eq,decoupled}} = 1$, we have to set $\lambda = 1$ for standard decoupled weight decay, which quickly pulls the weights to zero. On the other hand, with spectral clipped weight decay, we can simply set $\beta = 1$ and let the learning rate decay to zero throughout training, which is what we already do in practice anyway. This allows us to set $\lambda$ to a much smaller value, minimizing performance degradation while still keeping the weight norms in check.
In JAX, this can be implemented as follows,
def spectral_clipped_weight_decay(W: jax.Array, beta: float=1., lamb: float=0.5) -> jax.Array:
return (1-lamb) * W + lamb * spectral_hardcap(W, beta)
def spectral_clipped_decoupled_weight_decay(W: jax.Array, beta: float=1., lamb: float=0.5, learning_rate) -> jax.Array:
return spectral_clipped_weight_decay(W, beta, lamb * learning_rate)
4. An alternative approach via Higham’s Anti-Block-Diagonal Trick

In the previous sections, we apply our matrix function directly on $W$ resulting in nested applications of $\texttt{msign}$. However, this causes numerical issues because the errors from the inner $\texttt{msign}$ get amplified by the outer $\texttt{msign}$. Furthermore, spectral relu and spectral hardcapping fails entirely on inputs with large eigenvalues. This is because the $\frac{1}{2}W$ term has to be ‘cancelled’ out by the other terms which are composed of lower-precision matrix multiplications, thus tiny errors result in larger discrepancies in the final result.
Here, we will instead use Higham’s anti-block-diagonal trick (Higham, 2008). This allows us to compute $\texttt{msign}$ only once, reducing the complexity of the operations and numerical inaccuracies albeit at the cost of more compute and memory usage. Although 3-4x more costly than the nested approach, it may be worth it when we want to:
- Use it as the dualizer in our optimizer as a replacement for Muon’s orthogonalization step. The (spectral) norm of the gradients spikes during training for various reasons, and so having a more numerically stable implementation at larger scales is preferred; and
- Design linear attention mechanisms with the spectral clipping function as a “sub-network”. A neat property is that this would allow us to naturally scale test-time compute by scaling the number of steps in $\texttt{msign}$.
4.1. Symmetric spectral clipping
Theorem 6 (Higham’s Anti-Block-Diagonal Trick). Let $g: \mathbb{R} \to \mathbb{R}$ be an odd analytic scalar function, $W \in \mathbb{R}^{m \times n}$, and construct the block matrix $S \in \mathbb{R}^{(m+n) \times (m+n)}$ as,
$$S := \begin{bmatrix} 0 & W \\ W^T & 0 \end{bmatrix}$$and let $g(S)$ as the primary matrix function defined from the scalar function $g$. Then,
$$g(S) = \begin{bmatrix} 0 & g(W) \\ g(W)^T & 0 \end{bmatrix}$$and hence,
$$g(W) = [g(S)]_{12} = [g(S)]_{21}^T$$
Note that, for our optimization tricks below to work, our scalar function $\texttt{clip}_{[\alpha, \beta]}$ has to be odd which we will impose by setting,
$$\alpha = -\beta.$$Also note that,
$$\texttt{clip}_{[-\sigma_{max}, \sigma_{max}]}(x) = \sigma_{max} \cdot \texttt{clip}_{[-1, 1]}(x / \sigma_{max})$$and thus it would suffice to construct $\texttt{spectral\_clip}_{[-1, 1]}(\cdot)$ first and then,
$$\begin{equation} \texttt{spectral\_clip}_{[-\sigma_{max}, \sigma_{max}]}(W) = \sigma_{max}\cdot\texttt{spectral\_clip}_{[-1, 1]}(W / \sigma_{max}). \end{equation}$$Now, applying Theorem 6 with $g = \texttt{clip}_{[-1, 1]}$ yields,
$$\begin{equation} \texttt{spectral\_clip}_{[-1, 1]}(W) = \frac{1}{2}\left[ (I+S) \texttt{msign}(I+S) - (I-S) \texttt{msign}(I-S) \right]_{12} \end{equation}$$The following code implements this in JAX,
def _spectral_clip(W: jax.Array) -> jax.Array:
m, n = W.shape
I = jnp.eye(m + n, dtype=W.dtype)
S = jnp.block([[jnp.zeros((m, m), dtype=W.dtype), W], [W.T, jnp.zeros((n, n), dtype=W.dtype)]])
gS = (1/2) * (
(I + S) @ _orthogonalize_via_newton_schulz(I + S)
- (I - S) @ _orthogonalize_via_newton_schulz(I - S)
)
return gS[:m, m:] # read off the top-right block
def spectral_clip(W: jax.Array, sigma_max: float=1.) -> jax.Array:
return sigma_max * _spectral_clip(W / sigma_max)
Note that we are still calling _orthogonalize_via_newton_schulz twice here, which is not ideal either. Luckily, there’s a neat trick that allows us to compute it only once.
4.2. Optimization via abstract algebra (again)
First, notice that both
$$I + S = \begin{bmatrix} I_m & W \\ W^T & I_n \end{bmatrix}\qquad I - S = \begin{bmatrix} I_m & -W \\ -W^T & I_n \end{bmatrix}$$are block matrices of the form
$$\begin{bmatrix} P & Q \\ Q^T & R \end{bmatrix}$$where $P, R$ are symmetric matrices and $Q$ is an arbitrary matrix. It is a well-known result that such matrices form a linear sub-algebra $\mathcal{A}$, i.e., they are closed under addition, scalar multiplication, and matrix multiplication. This means that applying any polynomial function to these matrices will yield another matrix of the same form. And since we’re calculating the matrix sign function with Newton-Schulz iteration, which is a composition of polynomial functions, its result must also be of the same form.
Another neat property we can take advantage of is that flipping the signs of the anti-diagonal blocks gets preserved under application of any analytic matrix function.
Proposition 7 (Parity w.r.t. $Q \to -Q$ when applying analytic matrix function $f(\cdot)$). Let $A \in \mathcal{A}$ such that,
$$A := \begin{bmatrix} P & Q \\ Q^T & R \end{bmatrix}$$for some arbitrary matrix $Q \in \mathbb{R}^{m \times n}$ and symmetric matrices $P \in \mathbb{R}^{m \times m}$, $R \in \mathbb{R}^{n \times n}$, let $f: \mathcal{A} \to \mathcal{A}$ be an analytic matrix function, and let
$$\begin{bmatrix} \widetilde{P} & \widetilde{Q} \\ \widetilde{Q}^T & \widetilde{R} \end{bmatrix} := f(A) = f\left(\begin{bmatrix} P & Q \\ Q^T & R \end{bmatrix}\right).$$Then,
$$\begin{bmatrix} \widetilde{P} & -\widetilde{Q} \\ -\widetilde{Q}^T & \widetilde{R} \end{bmatrix} = f\left(\begin{bmatrix} P & -Q \\ -Q^T & R \end{bmatrix}\right).$$
This is a standard result. To see why,
Proof. Let $J = \text{diag}(I_m, -I_n)$ so that $J^2 = I$ and $J^{-1} = J$. This makes $J A J = J A J^{-1}$ simply a change of basis, which is preserved under application of analytic matrix functions. Thus we have,
$$\begin{aligned} Jf(A) J &= f(JAJ)\\ \begin{bmatrix} I_m & 0 \\ 0 & -I_n \end{bmatrix} \begin{bmatrix} \widetilde{P} & \widetilde{Q} \\ \widetilde{Q}^T & \widetilde{R} \end{bmatrix} \begin{bmatrix} I_m & 0 \\ 0 & -I_n \end{bmatrix} &= f\left(\begin{bmatrix} I_m & 0 \\ 0 & -I_n \end{bmatrix} \begin{bmatrix} P & Q \\ Q^T & R \end{bmatrix} \begin{bmatrix} I_m & 0 \\ 0 & -I_n \end{bmatrix}\right)\\ \begin{bmatrix} \widetilde{P} & -\widetilde{Q} \\ -\widetilde{Q}^T & \widetilde{R} \end{bmatrix} &= f\left(\begin{bmatrix} P & -Q \\ -Q^T & R \end{bmatrix}\right)\quad\blacksquare \end{aligned}$$
Thus we have,
$$\begin{bmatrix} \widetilde{P} & \widetilde{Q} \\ \widetilde{Q}^T & \widetilde{R} \end{bmatrix} = \texttt{msign}(I + S)\qquad\qquad \begin{bmatrix} \widetilde{P} & -\widetilde{Q} \\ -\widetilde{Q}^T & \widetilde{R} \end{bmatrix} = \texttt{msign}(I - S)$$for some $\widetilde{Q} \in \mathbb{R}^{m \times n}$ and symmetric $\widetilde{P} \in \mathbb{R}^{m \times m}$, $\widetilde{R} \in \mathbb{R}^{n \times n}$. Together with Equation 13, we get,
$$\begin{align} \texttt{spectral\_clip}_{[-1, 1]}(W) &= \frac{1}{2}\left[\begin{bmatrix} I_m & W \\ W^T & I_n \end{bmatrix} \begin{bmatrix} \widetilde{P} & \widetilde{Q} \\ \widetilde{Q}^T & \widetilde{R} \end{bmatrix} - \begin{bmatrix} I_m & -W \\ -W^T & I_n \end{bmatrix} \begin{bmatrix} \widetilde{P} & -\widetilde{Q} \\ -\widetilde{Q}^T & \widetilde{R} \end{bmatrix}\right]_{12}\nonumber\\ &= \frac{1}{2} \left[\begin{bmatrix} \widetilde{P} + W\widetilde{Q}^T & \widetilde{Q} + W\widetilde{R} \\ W^T\widetilde{P}+\widetilde{Q}^T & W^T\widetilde{Q}^T + \widetilde{R} \end{bmatrix} - \begin{bmatrix} \widetilde{P} + W\widetilde{Q}^T & -(\widetilde{Q} + W\widetilde{R}) \\ -(W^T\widetilde{P}+\widetilde{Q}^T) & W^T\widetilde{Q}^T + \widetilde{R} \end{bmatrix}\right]_{12}\nonumber\\ &= \begin{bmatrix} 0 & \widetilde{Q} + W\widetilde{R} \\ (\widetilde{Q} + \widetilde{P}W)^T & 0 \end{bmatrix}_{12} \label{eq:spectralclipblockwise} \\ \texttt{spectral\_clip}_{[-1, 1]}(W) &= \widetilde{Q} + W\widetilde{R}\qquad\text{ or }\qquad\widetilde{Q} + \widetilde{P} W\nonumber \end{align}$$This means that we only need to call msign once, and simply read off the blocks to compute the final result, leading to massive speedups. Also note that the diagonal blocks in Equation $\eqref{eq:spectralclipblockwise}$ are zero, which is what we expect from Theorem 6.
In JAX, this looks like the following:
def _spectral_clip(W: jax.Array) -> jax.Array:
m, n = W.shape
H = jnp.block([[jnp.eye(m, dtype=W.dtype), W], [W.T, jnp.eye(n, dtype=W.dtype)]])
OH = _orthogonalize_via_newton_schulz(H)
P, Q = OH[:m, :m], OH[:m, m:]
return Q + P @ W
# Q, R = OH[:m, m:], OH[m:, m:]
# return Q + W @ R
def spectral_clip(W: jax.Array, sigma_max: float=1.) -> jax.Array:
return sigma_max * _spectral_clip(W / sigma_max, 1)
And a codegolf version would be,
def spectral_clip_minimal(W: jax.Array, sigma_max: float=1., ortho_dtype=jnp.float32) -> jax.Array:
OH = _orthogonalize_via_newton_schulz(jnp.block([[jnp.eye(W.shape[0], dtype=W.dtype), W / sigma_max], [W.T / sigma_max, jnp.eye(W.shape[1], dtype=W.dtype)]]).astype(ortho_dtype)).astype(W.dtype)
return sigma_max*OH[:W.shape[0], W.shape[0]:] + OH[:W.shape[0], :W.shape[0]] @ W
# return sigma_max*OH[:W.shape[0], W.shape[0]:] + W @ OH[W.shape[0]:, W.shape[0]:]
4.3. Taking advantage of symmetry
The crux is that since both $I + S$ and $I - S$ are in the sub-algebra $\mathcal{A}$, Newton-Schulz iteration must preserve their block structure. Thus, we do not actually need to materialize the entire $(m + n) \times (m + n)$ block matrices. And note that,
$$\begin{aligned} \begin{bmatrix} P_i & Q_i\\ Q_i^T & R_i \end{bmatrix}\begin{bmatrix} P_j & Q_j\\ Q_j^T & R_j \end{bmatrix}^T &= \begin{bmatrix} P_i P_j + Q_i Q_j^T & P_i Q_j + Q_i R_j\\ Q_i^T P_j + R_i Q_j^T & Q_i^T Q_j + R_i R_j \end{bmatrix} \end{aligned}$$Thus we can implement the (block) matrix multiplications as,
@jax.jit
def block_matmul(
P1: jax.Array, Q1: jax.Array, R1: jax.Array,
P2: jax.Array, Q2: jax.Array, R2: jax.Array,
) -> Tuple[jax.Array, jax.Array, jax.Array]:
P = P1 @ P2 + Q1 @ Q2.T
Q = P1 @ Q2 + Q1 @ R2
R = Q1.T @ Q2 + R1 @ R2
return P, Q, R
and implement one step of Newton-Schulz iteration as,
def newton_schulz_iter(
P: jax.Array, Q: jax.Array, R: jax.Array,
a: float, b: float, c: float,
) -> jax.Array:
I_P = jnp.eye(P.shape[0], dtype=P.dtype)
I_R = jnp.eye(R.shape[0], dtype=R.dtype)
P2, Q2, R2 = block_matmul(P, Q, R, P, Q, R)
P4, Q4, R4 = block_matmul(P2, Q2, R2, P2, Q2, R2)
Ppoly = a * I_P + b * P2 + c * P4
Qpoly = b * Q2 + c * Q4
Rpoly = a * I_R + b * R2 + c * R4
return block_matmul(P, Q, R, Ppoly, Qpoly, Rpoly)
We then initialize the blocks as $P_0 = I_{m}$, $Q_0 = W$, and $R_0 = I_m$, apply Newton-Schulz iteration as described above to get $(\widetilde{P}, \widetilde{Q}, \widetilde{R})$, and finally return $\widetilde{Q} + W\widetilde{R}$ or $\widetilde{Q} + \widetilde{P} W$. This gives us efficiency gains vs. the naive implementation.
5. Runtime analysis
From Jordan et al. (2024), computing the matrix sign function on a $m \times n$ matrix (WLOG let $m \leq n$) via $T$ steps of Newton-Schulz iterations with 5th degree odd polynomials requires at most $\approx 6Tnm^2$ matmul FLOPs. Thus,
| Operation | Number of $\texttt{msign}$ calls | Total FLOPs | FLOPs overhead (w/ NanoGPT-140M speedrun configs) |
|---|---|---|---|
| $\texttt{msign}$ via Newton-Schulz | $1$ | $6Tnm^2$ | 0.98% |
| $\texttt{spectral\_clip}_{[\alpha, \beta]}$ (via nested $\texttt{msign}$ in Section 2) | $3$ | $(18T + 6)nm^2$ | 3.13% |
| $\texttt{spectral\_relu}$ | $2$ | $(12T + 4)nm^2$ | 2.08% |
| $\texttt{spectral\_hardcap}$ (Su’s (2025b) version) | $2$ | $(12T + 4)nm^2$ | 2.08% |
| $\texttt{spectral\_clipped\_weight\_decay}$ | $2$ | $(12T + 4)nm^2$ | 2.08% |
| $\texttt{spectral\_clip}_{[-\beta, \beta]}$ (via full-matrix anti-block-diagonal trick) | $1$ $(m+n) \times (m+n)$ | $6T(n+m)^3$ | 7.81% |
| $\texttt{msign}$ via block-wise Newton-Schulz | $1$ (block-wise) | $36Tn^3$ | - |
| $\texttt{spectral\_clip}_{[-\beta, \beta]}$ (via block-wise anti-block-diagonal trick) | $1$ (block-wise) | $(36T+1)n^3$ | 5.89% |
6. Experimental results [Under Construction]
This section is still under construction.
6.1. Anti-Block-Diagonal Trick leads to more numerically stable Spectral Hardcapping
In Section 4 we made the claim that the nested implementation of spectral hardcapping is numerically unstable on large inputs. To verify this claim, we randomly generate matrices of size $1024 \times 4096$ (the size of a MLP projection layer in the NanoGPT-medium speedrun) with various spectral norms, pass them to $\texttt{spectral\_hardcap}_{\beta=1}$ using the various implementations, and report the spectral norms of the results.
We label the fully-materialized implementation discussed in Section 4.2 as the “Dense Anti-Block-Diagonal Trick” and the blockwise implementation discussed in Section 4.3 as the “Sparse Anti-Block-Diagonal Trick”.

Observe that both the sparse and dense versions properly cap the spectral norms at 1, as expected. However, the nested version starts to fail even on inputs with spectral norms as small as 100. The approximation does get better with more Newton-Schulz iterations, but we may need an exponential number of iterations to get the desired result for larger inputs.
6.2. Weight constraints accelerate grokking (and improve robustness)

Note: we used an unreleased updated version of the Modula library (Bernstein, 2024) for this work. We will update this post with a link to experimt codes once the library is released.
An interesting phenomenon commonly observed in deep learning is that generalization happens long after training accuracy saturates, and when it does happen, it happens “suddenly”–in a relative sense. This is known as “grokking” (Power et al., 2022). More recent results have shown that failure to ‘grok’ could be partly attributed to the uncontrolled growth of weight norms when training with the Adam optimizer (Prieto et al., 2025). A neat property of the Muon optimizer is that the spectral norm of its weight updates are guaranteed to be equal to the learning rate, i.e. controlled (Bernstein et al., 2024). And it has been shown that Muon indeed accelerates grokking (Tveit et al., 2025).
Now if the uncontrolled growth of the weight norms is part of the reason why models fail to grok, then it is natural to ask,
Do weight and weight update constraints enable/accelerate grokking?
Our preliminary results here suggest that the answer is yes.
6.2.1. Experimental setup
We will largely follow the setup of Prieto et al.’s (2025) grokking experiments on the addition-modulo-113 ($y=(a + b) \% 113$) and multiplication-modulo-113 ($y=ab \% 113$) tasks. In all our experiment runs, we use 2-layer MLPs with width 200, embedding dimension of 113, and GeLU activations. We concatenate the embeddings of the inputs $a$ and $b$, resulting in an input dimension of 226, which we then pass to the succeeding linear layers.
Using the Modula library (Bernstein et al., 2024) for parametrizing neural networks, we use the matrix sign function as the dualizer for linear layers and we test various projection maps described in the previous sections. Note that without weight constraints, this simply reduces to the Muon optimizer. For the embedding layer, we simply cap the RMS norm of the embeddings to 1. We also use simple grid search for hyperparameter search, discarding configurations that do not allow the models to grok 100% of the time across 64 random seeds. We then report the median steps-to-grok and median lipschitz bounds of the best performing configurations for each projection map.
All weights are stored in bfloat16 and all operations are done in bfloat16 as well, to simulate more realistic training conditions.
6.2.2. Results
Without projection maps or weight constraints, the models fail to grok on both tasks with 1K steps, which is consistent with previous results (Prieto et al., 2025). They also fail to grok with the matrix sign function as the projection map, suggesting that constraining the weights to the Stiefel manifold is too strong of a constraint.
Interestingly, simply capping the RMS norms of the embeddings already allows the models to grok and rapidly at that: the median steps-to-grok for both the add-mod-133 and mul-mod-113 tasks are 227 and 233 steps, respectively. The downside is that the models have four to five orders of magnitude larger Lipschitz bounds, making them very sensitive to the inputs. We now treat this as our baseline.
Finally, spectral normalization, spectral hardcapping, and spectral clipped weight decay all also allow the models to grok consistently on both tasks within 1K steps. For spectral clipped weight decay, in particular, larger $\lambda$ leads to lower-Lipschitz (i.e., more stable) models that grok relatively slower and smaller $\lambda$ leads to higher-Lipschitz (i.e., less stable) models that grok relatively faster. And this trade-off between stability of the trained model and speed-to-grok seems to be predictable.
6.3 NanoGPT Speedrun results [Under Construction]
[NanoGPT Speedrun results will be added here]
Acknowledgements
Many thanks to Rohan Anil for initiating a discussion thread on the topic on Twitter, and to Arthur Breitman, You Jiacheng, and Su Jianlin for productive discussions on the topic. All remaining mistakes are mine.
How to Cite
@misc{cesista2025spectralclipping,
author = {Franz Louis Cesista},
title = {Fast, Numerically Stable, and Auto-Differentiable {S}pectral {C}lipping Via {N}ewton-{S}chulz Iteration},
year = {2025},
month = {June},
day = {23},
url = {https://leloykun.github.io/ponder/spectral-clipping/},
}
If you find this post useful, please consider supporting my work by sponsoring me on GitHub:
References
- Greg Yang, James B. Simon, Jeremy Bernstein (2024). A Spectral Condition for Feature Learning. URL https://arxiv.org/abs/2310.17813
- Tim Large, Yang Liu, Minyoung Huh, Hyojin Bahng, Phillip Isola, Jeremy Bernstein (2024). Scalable Optimization in the Modular Norm. URL https://arxiv.org/abs/2405.14813
- Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim (2025). Parallelizing Linear Transformers with the Delta Rule over Sequence Length. URL https://arxiv.org/abs/2406.06484
- Riccardo Grazzi, Julien Siems, Jörg K.H. Franke, Arber Zela, Frank Hutter, Massimiliano Pontil (2025). Unlocking State-Tracking in Linear RNNs Through Negative Eigenvalues. URL https://arxiv.org/abs/2411.12537
- Ali Behrouz, Zeman Li, Praneeth Kacham, Majid Daliri, Yuan Deng, Peilin Zhong, Meisam Razaviyayn, Vahab Mirrokni (2025). ATLAS: Learning to Optimally Memorize the Context at Test Time. URL https://arxiv.org/abs/2505.23735
- Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein (2024). Muon: An optimizer for hidden layers in neural networks. Available at: https://kellerjordan.github.io/posts/muon/
- Jianlin Su (2025a). Higher-order muP: A more concise but more intelligent spectral condition scaling. URL https://kexue.fm/archives/10795
- Jianlin Su (2025b). Calculation of spectral_clip (singular value clipping) via msign. Available at: https://kexue.fm/archives/11006
- Jianlin Su (2025c). Calculation of spectral_clip (singular value clipping) via msign (part 2). Available at: https://kexue.fm/archives/11059
- Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yongsheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, Zhilin Yang (2025). Muon is Scalable for LLM Training. URL https://arxiv.org/abs/2502.16982
- Qiang Liu (2025). Muon is a Nuclear Lion King. URL https://www.cs.utexas.edu/~lqiang/lionk/html/intro.html
- Higham, Nicholas J. (2008). Functions of Matrices: Theory and Computation. SIAM.
- Jiacheng You (2025). On a more efficient way to compute spectral clipping via nested matrix sign functions. Available at: https://x.com/YouJiacheng/status/1931029612102078749
- Arthur Breitman (2025). On using the matrix sign function for spectral clipping. Available at: https://x.com/ArthurB/status/1929958284754330007
- Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, Vedant Misra (2022). Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets. URL https://arxiv.org/abs/2201.02177
- Lucas Prieto, Melih Barsbey, Pedro A.M. Mediano, Tolga Birdal (2025). Grokking at the Edge of Numerical Stability. URL https://arxiv.org/abs/2501.04697
- Amund Tveit, Bjørn Remseth, Arve Skogvold (2025). Muon Optimizer Accelerates Grokking. https://arxiv.org/abs/2504.16041
- Jeremy Bernstein, Laker Newhouse (2024). Old Optimizer, New Norm: An Anthology. URL https://arxiv.org/abs/2409.20325
- Jeremy Bernstein (2025). The Modula Docs. URL https://docs.modula.systems/
- Zixuan Chen, Xialin He, Yen-Jen Wang, Qiayuan Liao, Yanjie Ze, Zhongyu Li, S. Shankar Sastry, Jiajun Wu, Koushil Sreenath, Saurabh Gupta, Xue Bin Peng (2024). Learning Smooth Humanoid Locomotion through Lipschitz-Constrained Policies. URL https://arxiv.org/abs/2410.11825
- Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, Volkan Cevher (2025). Training Deep Learning Models with Norm-Constrained LMOs. URL https://arxiv.org/abs/2502.07529